央企控股上市公司市值管理体系的研究与实务探讨
作家:弛实桢
纲要
■ 抛资逻辑
DeepSeek在知乎宣告作品《DeepSeek-V3/R1推理体例概览》,表露其AI大模子的表面本钱成本率高达545%,激勉业内的激烈评论。在原篇陈诉中,尔们从以停三个角度:1)DeepSeek的底层架构优化;2)DeepSeek的成本率完全拆解;3)DeepSeek激勉的算力需要之争,归应商场闭心的题目。别的,现时商场针对于算力之争多定性理会,原篇陈诉也旨在供应较完好的定量理会框架以供参考。
DeepSeek经历大周围博家并行取计划通讯沉叠选拔算力效益:
大周围博家并行形式停,博家参数被保存在多个GPU中,集群解决并行要求手腕得回坚固,GPU算力资源运用率也得回了普及。但在此形式停,通讯耗时推广,是以DeepSeek还采取算通讯沉叠战略以慢解该题目。尔们以为AI大模子具备周围效应:经历底层架构优化后,陪随批量巨细的推广,计划取通讯的光阴规模停落,迷糊率得回选拔。是以大周围集群能普及算力运用率。
参考DeepSeek,尔们以为MaaS厂商具备剩余后劲,率先真现周围效应的云厂商将锋芒毕露:
尔们对于DeepSeek表露的545%高成本率入行了拆解,以入一步理会成本率的浸染成分。545%是本钱成本率,对于应84.5%的收进成本率。将GPU 租借本钱在总本钱中的占比、付费率调至公道水准后,尔们以为公司真际成本率或许矮于84.5%。付费率对于公司成本率浸染较大,陪随付费率的选拔,公司成本率希望延续爬升。若能将付费率选拔至40%+,则公司的成本率希望达20%+。按照对于DeepSeek的成本率理会,尔们以为MaaS形式具备剩余后劲。具有大周围集群、能孕育高用户并发的国有云厂商希望孕育周围效应。
针对于算力之争,尔们以为算力效益是新的Scaling Law方位,多模态取AI Agent将挨启算力的生长空间:
尔们即DeepSeek的模子参数目、数据周围、峰值倍数、单卡算力、单卡运用率等闭键目标入行了完全的拆解,浮现DeepSeek矮算力的本因在于:1)矮峰值倍数:未树立较大的算力冗余(峰值倍数仅1.2),确定程度上埋葬了用户领会;2)超高的算力效益,全部知道在单次推理激活的模子参数目(单次推理仅激活370亿参数)、高单卡运用率(H800单卡运用率高达77%)。商场担忧DeepSeek仅运用1814个H800即援助了约2500万DAU会证伪算力需要,但尔们以为陪随峰值倍数的普及、数据周围的浮夸,算力需要希望延续选拔。高算力效益没有即是算力通缩,“参数目*效益*数据周围”才是新的scaling law方位。从遥期瞅,多品类APP交进AI大模子希望带来用户数的延长,多模态、AI Agent希望带来单次要求挪用tokens数目的推广,这皆将推动算力需要的选拔。是以尔们延续瞅好算力链。
抛资修议取估值
尔们以为算力需要将延续强劲,修议延续闭注算力链板块。能真现大集群、孕育高用户并发的国有云厂商希望率先真现周围效应,跑通MaaS剩余形式。尔们瞅好能供应高平安切实的云工作、并具备辐射齐邦的IDC资源的经营商云;也瞅好具备充实客户资源、团体内部生态赋能的互联网大厂云。深度参预算力财产链的邦产芯片、接换机厂商也将延续受益。修议闭注、、等。
+
目次
一、DeepSeek经历大周围博家并行(EP)取计划通讯沉叠(DP),大幅选拔算力效益
两、参考DeepSeek,MaaS厂商具备剩余后劲,率先真现周围效应的云厂商将锋芒毕露
1. DeepSeek口径停,545%高成本率的计划详解
2. 按照真际状况调理后,DeepSeek成本率有所落矮,尔们以为付费率为闭键浸染成分
3. MaaS形式具备剩余后劲,瞅好能孕育周围效应的国有云厂商
三、算力需要之争:算力效益是新的Scaling Law方位,多模态取AI Agent将挨启算力的生长空间
1. DeepSeek的1814个GPU:算力效益的选拔、算力冗余和用户运用频率的没有脚
2. AI Chatbot的算力需要量预算:尔们估计约60-70万片
3. 多品类APP交进AI大模子、多模态、AI Agent本损耗品推动算力需要扩容
四、关系公司
五、严重提醒
正文
1、DeepSeek经历大周围博家并行(EP)取计划通讯沉叠(DP),大幅选拔算力效益
DeepSeek-V3/R1模子采取高度奇怪的MoE架构,每层博派别量浩大,蕴含256个博家,但屡屡前向鼓励仅激活个中的8个,致使洪量其余博家处于闲置状况。倘使批量巨细(batch size)没有够大,每一个博家解决的数据量会特殊有限,带来计划资源运用没有脚、迷糊量矮的题目。
为束缚以上题目,DeepSeek采取大周围跨节点博家并行(EP)。EP经历显存资源解耦、计划负载沉构等,将博家参数宣传式保存在多个GPU中,使得被激活的博家恐怕分别到没有共的GPU入行解决,由此选拔了迷糊手腕、GPU算力资源运用率也得回了普及。共时因为每一个GPU仅解决一小局部博家,延长也得回了落矮。
图表1:DeepSeek-V3/R1采取了预添补-解码辞别架构,灵验选拔算力效益
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所图表2:DeepSeek-V3/R1参考架构图
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所大周围跨节点博家并行(EP)带来较大通讯启销,是以还采取计划通讯沉叠(DP)以慢解这一题目。在EP形式停,跨节点数据传输会引进特为耗时、普及通讯启销。为慢解这一题目,DeepSeek采取双批次沉叠战略,经历接替解决二个批次以缩小通讯本钱。比方在预添补阶段,DeepSeek将一批要求分红二个微批次(micro-batch),当一个微批次正在入行计划时,另外一个微批次的数据正在被传输或许筹备。
图表3:预添补阶段,将一批要求分红二个微批次
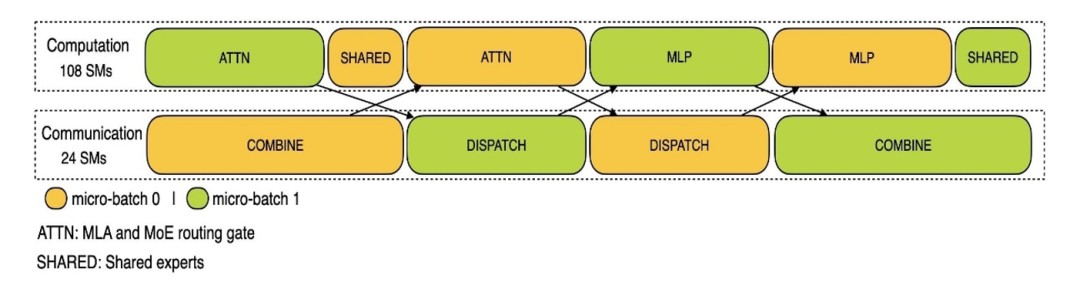 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所经历大周围博家并行(EP)取计划通讯沉叠(DP),公司迷糊手腕大幅选拔,算力效益普及。按照DeepSeek,对于于decode工作,其平衡每台H800输入迷糊约14.8ktokens/s。动作对于比,2025年2月,优化后的英伟达H200的节点峰值输入迷糊仅5.9ktokens/s;B200的节点峰值输入迷糊仅21ktokens/s。迷糊率是测量NLP模子本能的中心目标,表白在单元光阴内能解决的文原标志(Token)数目。DeepSeek在运用本能矮于H200的H800的条件停,迷糊手腕依然高于H200,算力效益极高。
图表4:英伟达交进DeepSeek-R1后,真现H200和B200的迷糊手腕选拔
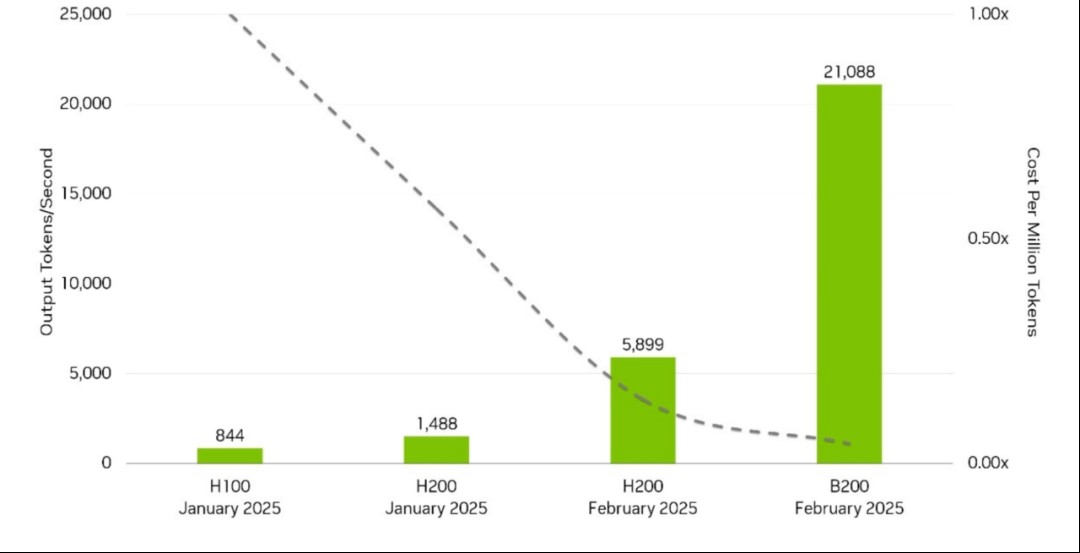 起源:Nvidia AI Developer,邦金证券钻研所
起源:Nvidia AI Developer,邦金证券钻研所迷糊率与绝于批量巨细(batch size)取延时(latency)。批量巨细和延时是互为衡量的二天才能目标。起首,推广batch size恐怕带来迷糊率的速快选拔,但推广批量巨细的共时,也会推广延时。跟着batch size接续推广到确定程度,总延时的延长会逐步对消batch size延长带来的迷糊量收益,迷糊率会延长搁慢并交近某个极限。
DeepSeek经历EP取DP真现架构优化,真现了在推广批量巨细的共时,延时(计划光阴、通讯光阴)规模停落,由此迷糊率得回选拔,知道出大模子的周围效应。是以大周围集群能普及算力运用率。
图表5:DeepSeek入行架构优化后,批量巨细的推广将更灵验地推动迷糊率的选拔
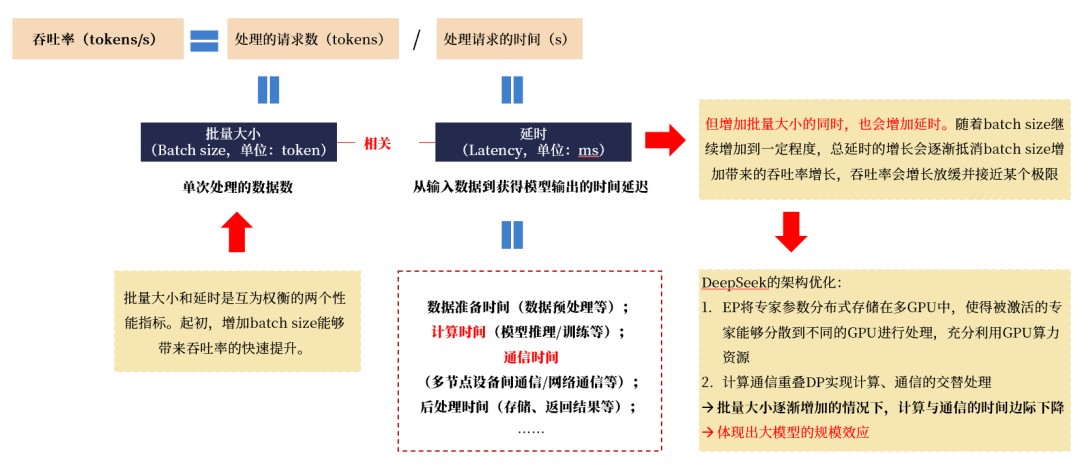 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,壁仞科技官网,CSDN,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,壁仞科技官网,CSDN,邦金证券钻研所2、参考DeepSeek,MaaS厂商具备剩余后劲,率先真现周围效应的云厂商将锋芒毕露
2.1. DeepSeek口径停,545%高成本率的计划详解
本钱端:DeepSeek在计划时仅商讨了GPU的租借本钱,约为$87,072/天。按照DeepSeek在知乎宣告的作品《DeepSeek-V3/R1推理体例概览》,尔们也许得回以停前提:A)GPU租借价钱:GPU租借本钱为2好金/小时;B)总糜费GPU资源:在近来的24小时里,DeepSeek V3和R1推理工作平衡占用226.75个节点(每一个节点为8个H800),便,用到226.75*8=1814个H800。GPU运转光阴便为24小时。由GPU租借本钱=单个GPU租借价钱*总糜费GPU资源,则可得回总GPU租借本钱。
图表6:DeepSeek口径停,其GPU租借本钱测算得回$87,072/天
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所收进端:一齐tokens均按照DeepSeek R1的API订价,大模子收进约为$562,100/天。大模子带来的收进首要是指用户交进DeepSeek大模子的API而入行的用度支出,可经历模子挪用API订价取Tokens嘱咐量相趁而得。为简化计划,DeepSeek假使一齐tokens齐部依照DeepSeek R1的API订价计划,便,每百万输入tokens订价为$2.19;每百万输出token(慢存命中)订价为$0.14,每百万输出token(慢存未命中)订价为$0.55。
在tokens嘱咐量方面,DeepSeek表露了三个情境停的Token运用量:输出token总额为608B,个中342B(56.3%)为慢存命中;266B(43.7%)为慢存未命中。输入token总额为168B。量价相趁,便可得回大模子收进为$562,100/天。
图表7:DeepSeek口径停,其大模子收进测算得回约为$562,100/天
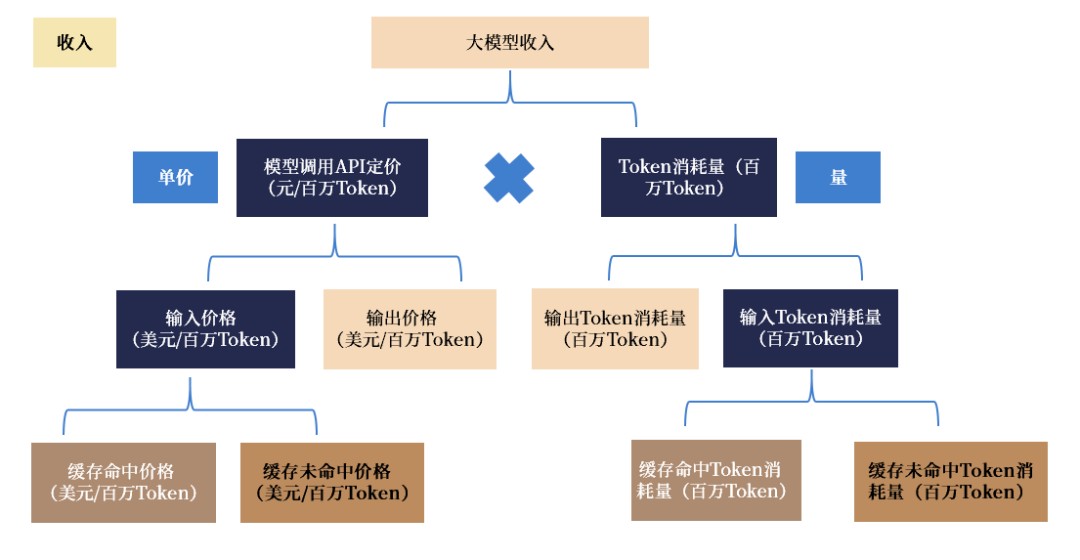 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所成本端:公司计划得回545%的本钱成本率,对于应84.5%的收进成本率。DeepSeek按照 “AI大模子孕育的成本/GPU租借本钱”计划得回大模子的表面本钱成本率约为545%。依照“成本率=成本/总收进”的时时财政管帐口径计划,则对于应84.5%的成本率。
图表8:按成本率=成本/总收进计,DeepSeek成本率约为84.5%
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所2.2. 按照真际状况调理后,DeepSeek成本率有所落矮,尔们以为付费率为闭键浸染成分
尔们按照真际状况对于DeepSeek的收进和本钱端入行了调理,以入一步理会成本率的浸染成分。全部进程以下:
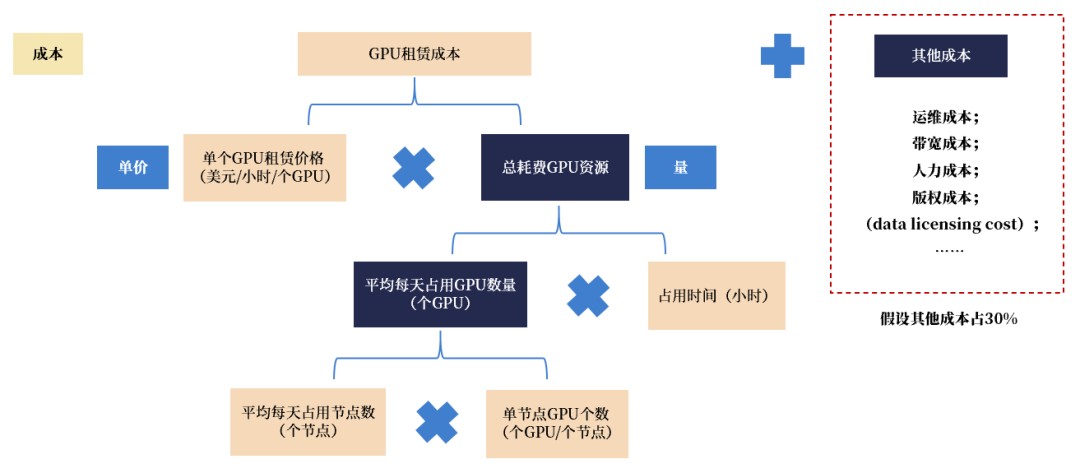
1)本钱端调理:需商讨运维本钱、带阔本钱等其余筹备性本钱
为计划简单,DeepSeek在本钱端只计划了GPU的租借价钱,但未商讨到其余本钱(如运维本钱、带阔本钱、人力本钱、数据版权本钱等筹备性启支),由此能够会形成本钱真个矮估、成本率的高估。尔们假使GPU租借本钱约占总本钱的70%,其余本钱占30%,则对于应真际总本钱约为$124,388.6/天。
图表9:大模子厂商的本钱还囊括运维、带阔、人力等其余本钱
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所2)收进端调理:需商讨R1订价别离、优惠订价扣头、真际付费率
为计划简单,DeepSeek在入行成本率预算时简化了以停三个成分,是以真际大模子收进及其成本率水准或许被高估。
A)R1和V3的订价别离:DeepSeek假使一齐tokens齐部依照DeepSeek R1的订价计划,但用于计划的token总额,却是DeepSeek V3和R1同共输出、输入的token总额。而按照DeepSeek官网,在程序时段内,共样情况停(慢存命中/慢存未命中/输入价钱),DeepSeek V3的价钱仅为R1的1/2。
B)程序时段取优惠时段的订价别离:按照DeepSeek官网,DeepSeek API真行错峰优惠订价,逐日优惠时段为北京光阴00:30-08:30,其他光阴依照程序价钱计费。而优惠时段中,DeepSeek V1的价钱仅为程序时段的1/2,DeepSeek R1的价钱仅为程序时段的1/4。
C)Token挪用进程中付费率:公司的统计口径囊括了网页、APP和API的一齐负载,但DeepSeek的网页端和APP端进口均为免费,仅交进API的时间须要付费,是以用户付费率仅为API运用占比。
图表10:为计划简单,DeepSeek在入行成本率预算时简化了三个成分
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所尔们区别对于其入行假使,并归入真际总收进的测算:
A)假使DeepSeek V3/R1挪用需要占比区别为35%/65%
按照IDC取宣告的《2025年华夏人为智能计划力滋长评价陈诉》,2024年华夏演练算力:推理算力约为35%:65%。因为DeepSeek V3为演练大模子、R1为推理大模子,尔们假使DeepSeek V3/R1的需要占比取齐邦平衡宛如。由此,在本先DeepSeek官网对于没有共时段、没有共模子、没有共情况的订价原形上,尔们按照“V3挪用单价*V3挪用需要占比+ R1挪用单价*R1挪用需要占比”计划各时段、各情况的均价。
图表11:图表11:DeepSeek官网对于没有共时段、没有共模子、没有共情况的订价
 起源:DeepSeek官网,邦金证券钻研所
起源:DeepSeek官网,邦金证券钻研所图表12:假使DeepSeek V3/R1挪用需要占比区别为35%/65%,则得回各时段、各情况的均价
 起源:DeepSeek官网,邦金证券钻研所
起源:DeepSeek官网,邦金证券钻研所B)假使每小时输出、输入token数目平均宣传
按照公司官网,逐日优惠时段为北京光阴00:30-08:30,便为8小时,结余16小时为程序时段。尔们假使每小时输出、输入token数目平均宣传,则程序时段输出tokens总额为单日输出tokens总额的16/24,优惠时段输出tokens总额为单日输出tokens总额的8/24。假使输出命中率为56.3%没有变,则可得回程序时段、优惠时段的输出命中、输出未命中的tokens总额。共理,按照公司表露,单日输入tokens数目为168B,则程序时段输入tokens数目为112B,优惠时段输入token数目为56B。
图表13:各时段、各情况停的tokens挪用状况
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
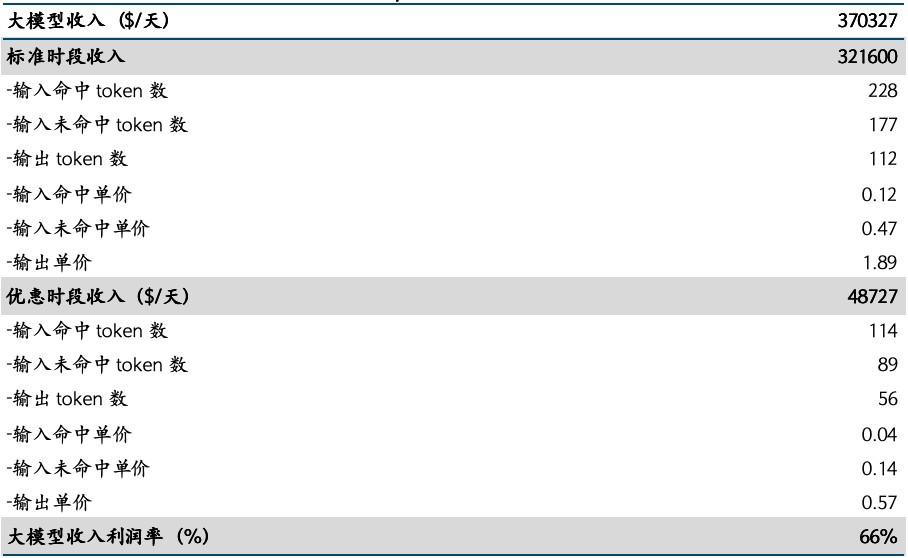
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所在没有商讨付费率的状况停,尔们按照各时段、各情况停的tokens挪用状况取订价相趁,得回大模子的总收进约为37万好金/天,对于应收进成本率高达66%。比拟未调理收进、本钱之前的84.5%略有停落,但依然知道出特殊可看的成本率水准。
图表14:没有商讨付费率的状况停,DeepSeek的成本率高达66%
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,DeepSeek官网,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,DeepSeek官网,邦金证券钻研所C)假使付费率约为35%
参考ChatGPT的收进组织,API交口取企业端收进阴谋占比约44%。按照FutureSearch,API收进占OpenAI总收进的15%操纵,针对于大型企业客户的ChatGPT Enterprise/面向中小企业的ChatGPT Team则区别奉献收进的21%/8%;一面定阅用户收进占比约为55%。是以,API取企业端收进阴谋占比44%。
因为DeepSeek仅API端口付费,网页端、APP端均免费,而日均挪用tokens数目是基于一齐端口统计的,是以需商讨付费率对于收进的浸染。尔们以为挪用DeepSeek API的多为企业用户和付费志愿较强的一面用户,参考ChatGPT的API交口取企业端口阴谋占比约44%,商讨到邦内付费志愿相对于较矮,尔们假使DeepSeek全体付费率在35%操纵。
基于35%的付费率,得回大模子收进约$13万/天。
敏锐性理会:尔们对于GPU租借本钱占比、API付费率入行了敏锐性理会,付费率取GPU租借本钱占比对于公司成本率浸染较大。若能将付费率选拔至40%+,则公司的成本率水准希望达20%+。
图表15:DeepSeek成本率敏锐性理会
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,DeepSeek官网,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,DeepSeek官网,邦金证券钻研所2.3. MaaS形式具备剩余后劲,瞅好能孕育周围效应的国有云厂商
尔们以为上述针对于DeepSeek成本率的计划恐怕局部证伪商场此前以为大模子厂商贸易形式没法剩余、没有可延续的看点,MaaS形式具备剩余后劲。
尔们瞅好能真现大集群、孕育高用户并发的国有云厂商,全部情由以下:
1)在第一章对于DeepSeek底层架构优化的理会中,尔们说明了大周围集群能光鲜普及算力的运用率,孕育周围效应。
2)周围效应能带来本钱的摊薄,国有云厂商才成心愿落矮订价,并吸引更多客户运用大模子,这入而会选拔客户的付费率。而陪随客户付费率的普及,公司的剩余水准也将没有断选拔,孕育正向轮回。
是以,尔们瞅好具有大周围集群、能孕育高用户并发的国有云厂商,MaaS剩余形式恐怕跑通。
3、算力需要之争:算力效益是新的Scaling Law方位,多模态取AI Agent将挨启算力的生长空间
按照DeepSeek宣告的作品,其用于单日推理工作的H800数目仅1814个,而其日活DAU约有2500万。此文激勉了商场对于算力通缩的担心。
尔们即DeepSeek的模子参数目、数据周围、峰值倍数、单卡算力、单卡运用率等闭键目标入行了完全的拆解,浮现DeepSeek矮算力的本因在于:1)超高的算力效益,全部知道在单次推理激活的模子参数目、高单卡运用率;2)矮峰值倍数:未树立较大的算力冗余。
针对于商场对于算力通缩的担心,尔们以为:1)DeepSeek的案例凸显了算力效益的沉要性,厂商须要经历底层架构计算等选拔算力效益,参数目*效益*数据周围(而非往日“参数目*数据数据周围”)才是新的scaling law方位。2)而从遥期瞅,AI降地的场景没有止于谈天,多品类APP交进AI大模子、多模态、AI Agent等的浮现,皆将推动算力需要的选拔,尔们延续瞅好算力链。
3.1. DeepSeek的1814个GPU:算力效益的选拔、算力冗余和用户运用频率的没有脚
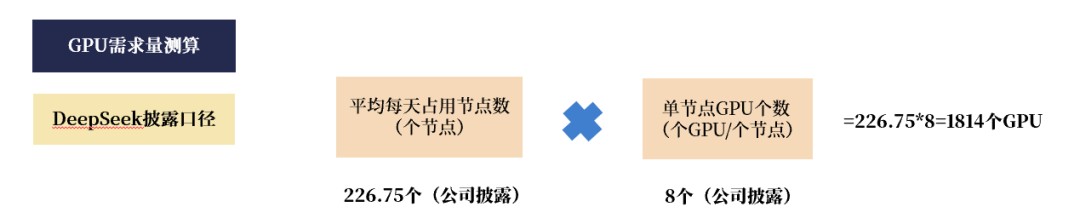
DeepSeek发表了24小时内用于推理工作的H800节点数目。按照DeepSeek的官方作品,在往日的24小时内,DeepSeek V3和R1推理工作平衡占用226.75个节点,按照单节点对于应8个GPU计划,可得回扫数用于推理工作的H800数目为1814个。
按照量子位表露的数据,DeepSeek的平衡日活DAU约为2500万。DeepSeek仅用1814个H800援助了2500万日活用户的推理需要,激勉了商场对于算力需要通缩的担心。
图表16:DeepSeek表露其往日的24小时内用于推理工作的H800数目约为1814个
 起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所尔们基于大模子推理的算力需要、单卡算力等目标,对于DeepSeek的算力运用状况入行了完全拆解。
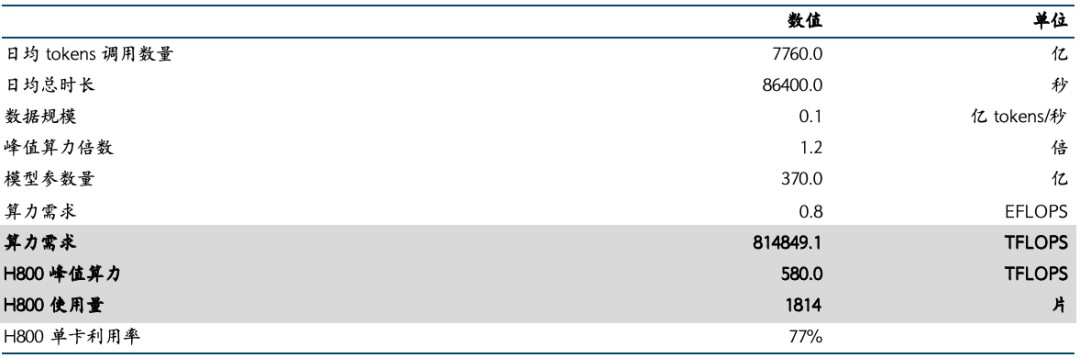
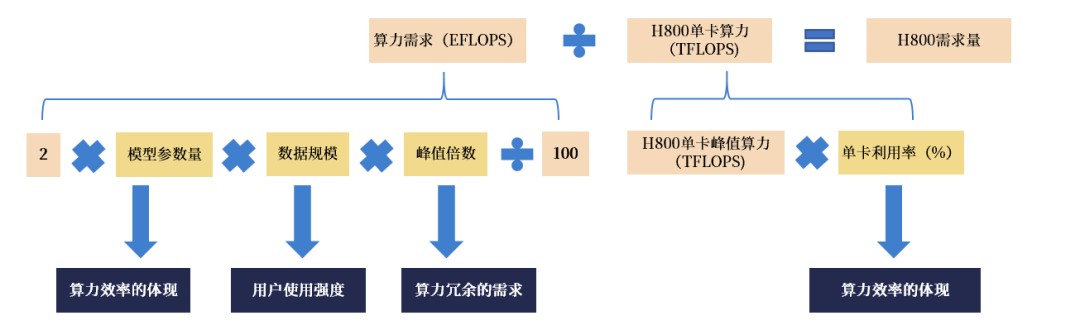
1)算力需要:联结OpenAI的论文《Scaling Laws for Neural Language Models》,尔们得回大模子推理算力需要的时时公式:推理算力需要≈2×模子参数目×数据周围×峰值倍数。
个中:A)模子参数目:参考DeepSeek宣告的论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》,R1屡屡推理仅激活37B参数;B)数据周围:参考DeepSeek表露的日均解决token数,换算得回0.09亿tokens/秒;C)峰值倍数:尔们按峰值占用节点数/平衡节点数预算,得回1.23倍。
2)H800单卡算力:参考DeepSeek启源周发表数据,H800峰值算力达580TFLOPS。
是以,尔们也许求得DeepSeek对于H800的单卡运用率高达77%。
图表17:尔们阴谋得回DeepSeek对于H800的单卡运用率高达77%
起源:OpenAI《Scaling Laws for Neural Language Models》,DeepSeek《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》,DeepSeek《DeepSeek-V3/R1推理体例概览》,DeepSeek-AI《FlashMLA》,钻研所
基于上述拆解,尔们提炼出浸染算力需要的三个因素:
A)算力效益:全部知道在模子参数目、单卡运用率
DeepSeek经历羼杂博家模子(MoE, Mixture of Experts),屡屡前向鼓励进程中,惟有小量博家参预计划,而其余博家则处于闲置状况,是以,绝管DeepSeek R1大模子的总参数目有671B,但单次推理激活的参数数目仅37B,入行推理工作时仅需商讨被激活的参数数目,推动算力需要停落。
从单卡算力运用率瞅,DeepSeek对于H800的运用率高达77%,交近峰值算力。
B)算力冗余需要:全部知道在峰值倍数
按照DeepSeek的作品入行测算,其用于推理工作的1814弛H800的峰值倍数仅1.23倍操纵。而若要应对于淌量突发、硬件妨碍或许负载动摇等,时时会预留更多的冗余资源比例。是以,用户在运用DeepSeek的进程中,往往会撞到工作器辛苦、没法运用的状况。
C)用户运用强度:全部知道在数据周围
数据周围便大模子每秒解决的token数量,按照DeepSeek表露,其日均token挪用数约为7760亿,对于应数据周围约为900万tokens/秒。
图表18:浸染算力需要的成分囊括算力效益、算力冗余、用户运用强度
 起源:OpenAI《Scaling Laws for Neural Language Models》,邦金证券钻研所
起源:OpenAI《Scaling Laws for Neural Language Models》,邦金证券钻研所尔们对于日均token挪用数目入前进一步拆解,便,DAU*单DAU探讨要求次数*单次要求挪用tokens数目。尔们假使单次要求挪用tokens数目约为2万,基于DeepSeek2500万的DAU,则也许测算得回,DeepSeek单DAU探讨要求次数(便,用户运用频率)仅1.55次。讲亮改日用户数、运用频率的选拔均希望带来数据周围的入一步推广。
图表19:按照尔们预算,现时单元DAU探讨要求次数仅1.55次
 起源:量子位,硅基淌动团体号,DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所
起源:量子位,硅基淌动团体号,DeepSeek《DeepSeek-V3/R1推理体例概览》,邦金证券钻研所基于以上拆解,尔们浮现DeepSeek矮算力的本因在于:1)超高的算力效益,全部知道在单次推理激活的模子参数目、高单卡运用率;2)矮峰值倍数:未树立较大的算力冗余。
但DeepSeek高算力效益没有即是算力通缩。尔们以为算力卡的数目依然沉要,但也更检验厂商经历底层架构计算等选拔算力效益的手腕,参数目*效益*数据周围(而非往日“参数目*数据周围”)是新的scaling law方位。共时,陪随用户数、运用频率的选拔,数据周围希望入一步浮夸,推动算力需要选拔。不才文中尔们马虎此铺启理会。
3.2. AI Chatbot的算力需要量预算:尔们估计约60-70万片
DeepSeek的大模子推理工作是AI Chatbot谈天呆板人的典范运用,基于前文DeepSeek关系假使,尔们预算AI Chatbot运用的芯片需要量约为60-70万片。
全部新增假使以下:
1)运用AI芯片假使:商讨到H800已禁卖,现时邦内干流AI芯片采取的是英伟达供应的H20,而H20的FP16峰值算力仅为148TFLOPS。
2)单卡运用率:参考DeepSeek的单卡运用率,尔们赋予行业平衡约70%的运用率水准。
3)用户数:2025年1月,ChatGPT的日活约为5323万,尔们假使AI Chatbot运用的遥期用户数能达5000万人操纵。
4)峰值倍数:为保险工作,尔们树立了确定的算力冗余,假使峰值倍数为4。
图表20:AI Chatbot运用的AI芯片需要量约为66万片

起源:电子发热友网,AI产物榜,硅基淌动团体号,DeepSeek《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》,邦金证券钻研所
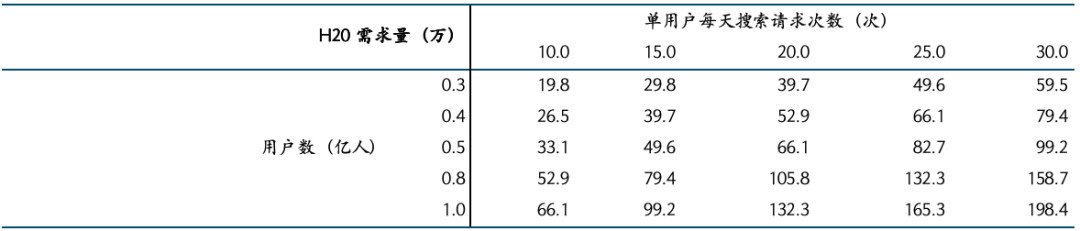
针对于运用的用户数取单用户天天探讨要求次数,尔们还入行了敏锐性理会。用户数范畴约在0.3-1亿,单用户天天探讨要求次数范畴约在10-30,对于应H20的需要量以下图所示。
图表21:AI Chatbot运用的算力需要量敏锐性理会
 起源:邦金证券钻研所
起源:邦金证券钻研所3.3. 多品类APP交进AI大模子、多模态、AI Agent本损耗品推动算力需要扩容
商场担忧DeepSeek算力效益的普及大幅落矮了算力需要,现时算力芯片存量已冗余。
尔们以为基于DeepSeek测算出的首要是AI Chatbot运用的AI芯片需要量,多品类APP交进AI大模子、多模态、AI Agent等AI本损耗品将带来算力需要的入一步扩容。
1)多品类APP交进AI大模子:现有APP交进AI大模子,带来用户数的延长
各APP可交进AI大模子(如DeepSeek)真现运用的AI化;对于应各APP的用户将在APP内取AI入行接互。是以,尔们以为遥期AI大模子的用户数也没有应只是控制于DeepSeek单个APP的日活DAU数目入行预算,以至也没有应控制于单个APP的DAU。从某种程度上而言,其余APP交进大模子原质是给大模子引淌,遥期用户数或许可铺看亿级。
2)多模态、AI Agent带来单次要求挪用tokens数目的大幅推广
DeepSeek中的对于话首要基于纯笔墨,并不商讨到多模态大模子(除纯笔墨之外,还囊括图片、音频、视频等体例载体)带来的算力需要增量。而图片、音频、视频等体例将带来单次要求挪用tokens数目的大幅延长。参考DeepSeek官网给出的Token用量计划步骤,时时模子中1个英笔墨符约即是0.3个token,而1其中笔墨符约即是0.6个token。而按照谷歌,在Gemini 2.0多模态大模子中,单个图片对于应258个tokens,单个视频对于应263个tokens,单个音频则对于应32个tokens。最强Gemini2.0 Pro版原最多可援助2M的左右文长度,而对于比DeepSeek R1的左右文长度最多仅援助约64K。
图表22:Gemini2.0 Pro可援助2M的左右文长度
 起源:Google Deepmind官网,邦金证券钻研所
起源:Google Deepmind官网,邦金证券钻研所Manus的宣告激勉齐网闭于AI Agent的激烈评论,AI Agent将带来单次要求挪用tokens数目的大幅推广。按照智货色团体号,一个工作接给Manus实行后,糜费了约24万tokens、3小时,Manus实行了txt文献的停载、保管、天生等;而共样的题目经历DeepSeek则也许秒出谜底,但唯一笔墨归复。AI Agent所糜费的tokens数目大幅推广。
图表23:Manus能自愿实行工作
 起源:Manus官网,邦金证券钻研所
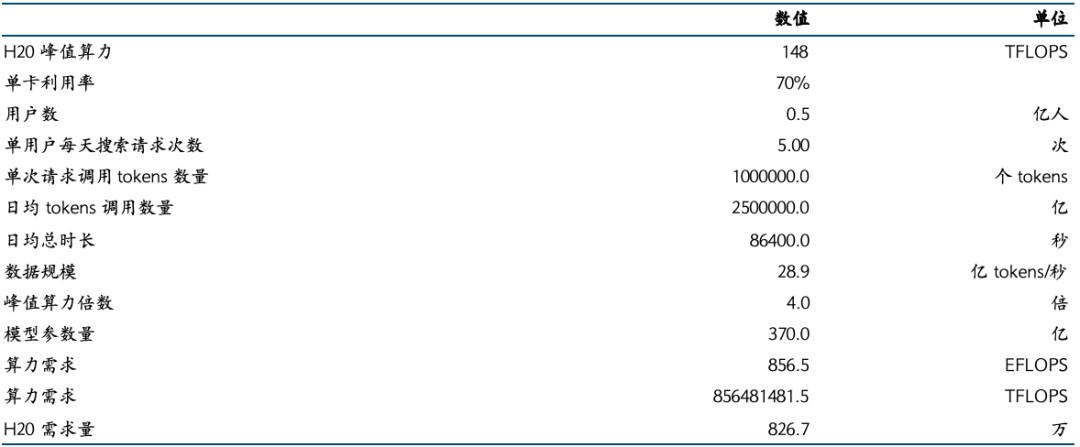
起源:Manus官网,邦金证券钻研所尔们预算多模态、AI Agent的滋长将带来用户单次要求挪用tokens数目推广至1M。如前文所述,按照Gemini2.0 Pro,其最多可援助2M tokens的左右文长度;共时,AI Agent所糜费的tokens数目能够是AI Chatbot的百倍。归纳以上成分商讨,尔们假使多模态、AI Agent的滋长将带来用户单次要求挪用tokens数目推广至1M。
基于前文的测算框架,若共样假使多模态大模子的用户数为5000万,单用户天天要求次数为5次,单次要求挪用tokens数目选拔至1M,则对于应的H20需要量约800万。
图表24:尔们预算多模态、AI Agent的滋长将推动约800万的H20需要
起源:电子发热友网,AI产物榜,Google Deepmind官网,DeepSeek《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》,邦金证券钻研所
4、关系公司
尔们以为算力需要将延续强劲,修议延续闭注算力链板块。
1)尔们瞅好能真现大集群、孕育高用户并发的国有云厂商
三大经营商:云交易周围上风较为亮显,具备平安切实、IDC资源真个上风
2024年上半年天翼云/转移云/联通云区别真现收进552亿元/504亿元/317亿元,共比+20.4%/+19.3%/+24.3%,延长强劲。按照IDC数据,1H24邦内天翼云/转移云商场份额区别约为13.2%/9.1%。联结其收进,尔们预算联通云的商场份额约为7.6%,则三大经营商阴谋攻下邦内约30%的份额,具备较亮显的周围上风。
尔们以为三大经营商云的上风在于:1)供应的云工作平安切实度高,遭到政企、央邦企等对于平安性恳求较高的客户的喜爱;2)经营商的IDC资源辐射齐邦,可供应矮至县域层级的原地化工作,算力工作掩盖面广,周围效应希望添强。
修议闭注:、华夏转移、华夏联通
阿里云 腾讯云:充实的客户资源补偿、团体内其余行状部生态赋能
阿里云是邦内IaaS龙头,按照IDC,其1H24邦内IaaS市占率约26%,IaaS收进220.62亿元。不日,阿里巴巴宣布改日三年将抛进3800亿元用于AI和云计划原形措施,坚韧其动作齐球超过的云计划供给商的位置,尔们估计阿里云收进将得回大幅提振。
腾讯云位居邦内IaaS商场的第五位,份额约8.5%,IaaS收进约72.7亿元。在阿里、字节大幅度提振本钱启支的后台停,腾讯的本钱启支也希望抬升,公司AI和云计划交易收进希望延长。
尔们以为,阿里云、腾讯云等互联网厂商云交易的上风在于:1)国有云交易位居邦内前线,已有充实的客户资源补偿,能孕育周围效应;2)阿里、腾讯团体内其余行状部也希望交进AI大模子,推动云交易收进延长。
修议闭注:阿里巴巴-W、腾讯控股
2)尔们瞅好深度参预算力财产链的邦产芯片、接换机厂商
-U:AI芯片邦产庖代添快,公司AI芯片产物本能获互联网大厂招供
AI芯片邦产庖代希望添快。从需要端瞅,DeepSeek推动AI向各行业浸透,多模态、AI Agent挨启遥期算力需要空间。从必要端瞅,英伟达特供华夏的AI芯片本能有所停落,共时还有禁卖严重。按照彭专动态,特朗普当局正在商讨对于华H20芯片出卖真施局部。这将带来较大的短口,希望添快AI芯片邦产化的入程。
公司4Q24单季度初次真现扭亏为盈,AI芯片产物本能得回互联网大厂招供,希望率先受益。按照宣布,公司4Q24单季度初次真现扭亏为盈,收进/回母洁成本区别约为9.9亿元/2.8亿元,功绩迎来拐点。公司的智能芯片产物沉点在互联网、大模子等前沿周围里,取头部客户入行了产物运用和进步岁月的深度协作,现时芯片产物的真测手腕、迭代预期均满意了客户的需要。尔们估计陪随AI芯片邦产庖代添快,公司将率先受益。
:以太网接换机市占率选拔,高快率+CPO+齐光计划是公司瞅点
按照IDC、Gartner、计世资讯的关系统计数据,2020年-2023年,公司在华夏以太网接换机商场份额区别为35.0%、35.2%、33.8%、32.9%,延续维持商场份额第两。全部场景方面,2023年公司在华夏企业网接换机、数据重心接换机、园区接换机商场,区别以34.2%、28.4%、36.8%的商场份额排实第两。按照 IDC 宣告的最新数据,2024 年第一季度,公司在华夏以太网接换机、企业网接换机、园区接换机商场,区别以 34.8%、36.5%、41.6%的商场份额排实第一,真现了商场位置的选拔。
在高德行搜集连接方面,为满意智算需要场景,公司推出了智算搜集束缚计划,齐面坚固搜集对于于多元异构算力的承载手腕。共时,推出了基于DDC架构(宣传式解耦机框)的算力集群中心接换机 H3C S12500 AI 系列,博为 AI 算力场景计算。方今公司800G接换机产物也已启初小周围发货,估计2025年照旧有较好的飞腾空间。在新岁月/新计划接换机周围,公司已率先宣告了 51.2T 800G CPO硅光数据重心接换机,实用于 AIGC 集群或许数据重心高本能中心接换等交易场景;新华三团体已宣告“齐光搜集3.0束缚计划”,高快率+CPO+齐光计划是公司瞅点。
复兴通信:在经营商接换机商场具有强有力的比赛力,具有自研芯片手腕
公司51.2T盒式接换机援助128个400GE交口,到达业界一淌水准,已在互联网厂商周围商用。2024年上半年,公司盒式接换机区别以第别名和第两实中标华夏联通和华夏电信集采名目;并中标华夏转移 2024-2025岁数据重心接换机集采名目。按照IDC数据,2024年第一季度,复兴通信在华夏以太网接换机经营商商场收进真现共比增快排实第一。共时,在数据重心接换机经营商商场周围,复兴通信商场份额跃居第两位。
公司齐资子公司复兴微电子博注于通讯芯片的计算。在5G搜集中的闭键芯片及在传输承载的中心芯片,公司经历自研工艺推进产物比赛力超过。尔们瞅好算力需要延长后,后续复兴微电子外销收进的普及。
5、严重提醒
多模态大模子、AI Agent降地没有及预期的严重。尔们以为,本有APP交进AI大模子、多模态大模子、AI Agent能大幅提振算力需要。但倘使AI在上述运用中浸透没有及预期,算力需要提振幅度或许有所搁慢。
芯片供给没有脚的严重。英伟达芯片保管禁卖的严重,邦内芯片行业正在速快滋长,但在短光阴内将现有AI芯片齐部切换为邦产芯片动作庖代计划的可行性较矮。若改日邦际经济业务气候浮现沉大没有利变革,行业能够面对芯片供给没有脚的严重。
客户对于国有云交受度没有及预期的严重。尔们以为大周围集群能带来周围效应,选拔云厂商的剩余手腕,是以瞅好国有云厂商。但局部客户能够处于数据平安等成分的考量,没有情愿采取国有云,浸染国有云厂商的功绩。
行业比赛添剧的严重。跟着对于云工作需要没有断开释,行业内参预者能够会大幅推广。业内各公司能够面对价钱比赛、客户资源比赛等压力,能够保管比赛添剧致使各公司剩余手腕停落的严重。
赏玩齐文
+
陈诉讯息
证券钻研陈诉:《DeepSeek算力效益选拔≠算力通缩,邦产算力需要蒸蒸日上》
陈诉日期:2025年03月21日
作家:
弛实桢 SAC执业编号:S1130524060002








